Just a quick update on this event to break up all the technical stuff.
I attended the Talking Agile - Developer Manager's Breakfast hosted by Microsoft at Buitengeluk this morning. I must commend the organisers for putting a top class event together, the venue, food and facilities where excellent and well run.
Of the speakers, well this was a mixed bag, Ernest Mnkandla, senior lecturer at the University of Johannesburg was disappointing, one was hoping that he would offer some insights into the agile process and present some new research on the topic, considering his academic pedigree.
But his presentation turned into a lecture on the history of agile and a run down of the different flavours of agile, anyone having read Fowler and Ambler would have got very little out of his talk.
Ahmed Salijee gave us a sneak preview of some agile enhancements to Team server coming in Visual Studio 2010, lots of report automation and labour saving wizardry. He continues to be a great speaker.
The best talk of the day was Clifford De Wit, he gave a to the point, insightful talk on practically implementing agility into development teams,very process focused. He talks allot of sense and should publish his ideas formally as they represent a realistic and tried methodology that would be welcomed by many.
As always there was some product spiel, but all in all a good session made worthwhile by Clifford and Ahmed, well done guys.
Wednesday, November 5, 2008
Tuesday, October 14, 2008
Part 2 - Designing the manager services
This stage is probably the most crucial as it will determine the emergent properties of your system; this is how your system behaves while in operation. Luckily there are a number of things that we can look at introducing so that we are steered down the right path. Some of these are:
Decentralization: Use fully decentralized techniques to remove scaling bottlenecks and single points of failure.
Asynchrony: The system makes progress under all circumstances.
Autonomy: The system is designed such that individual components can make decisions based on local information.
Local responsibility: Each individual component is responsible for achieving its consistency; this is never the burden of its peers.
Controlled concurrency: Operations are designed such that no or limited concurrency control is required.
Failure tolerant: The system considers the failure of components to be a normal mode of operation, and continues operation with no or minimal interruption.
Controlled parallelism: Abstractions used in the system are of such granularity that parallelism can be used to improve performance and robustness of recovery or the introduction of new nodes.
Decompose into small well-understood building blocks: Do not try to provide a single service that does everything for everyone, but instead build small components that can be used as building blocks for other services.
Simplicity: The system should be made as simple as possible (but no simpler).
Just a note at this stage, this type of architecture is for enterprise type systems, these are systems deployed within a organization that run the critical business process, things like data integrity and security are vital. There are many other styles of architecture and we can go into others in future posts. I have a strong bias towards WCF as I believe it to be the most productive framework for building this type of architecture.
I recommend a closed architecture, where objects are allowed to call other objects only in their own tier or in the tier immediately under them. This encapsulates changes and eases the task of long-term maintenance.
At the service boundary services need to support business capabilities, they should have an interface that can be thought of what a business does, and an interface that can the thought of how the business currently does that process. Key here is to keep the what, and the how decoupled from each other.
Decoupling is the cornerstone of modern development, look at the modern patterns that we as an industry subscribe to, notice something? They all hold as a central tenant this notion of decoupling, the removing direct dependency on concrete objects and the enabler of this, dependency injection.
Interfaces allow us to achieve the separation between what and how, so we should take things that are good and try using them elsewhere. Don’t get me wrong, coupling is not all bad we need to be coupled to thing in order for our application to be useful, the decision of choosing what to be coupled to becomes critical.
I have observed that as soon as IT assets and components map well to the real world things work well and systems become really useful. I mentioned earlier that the top level services should map to business capabilities, what are these?
A business capability is a particular ability or capacity that a business may possess or exchange to achieve a specific purpose or outcome. A capability describes what the business does (outcomes and service levels) that create value for customers; for example, pay employee or ship product. A business capability abstracts and encapsulates the people, process/procedures, technology, and information into the essential building blocks needed to facilitate performance improvement and redesign analysis.
So to achieve stable, useful boundary services i.e. the ones exposed to the business people, we need to align them with business capabilities, one technique of achieving this is capability mapping and when applied correctly leads to process driven services.
One of our top non functional is maintainability as the amount of time a system spends in development pales in comparison to the amount of time it will spend in maintenance. With that in mind, the granularity and size of our services should be thought about. Services with hundreds of methods will be un-maintainable while services with one method will be useless; the trick is to find the area of minimum cost between the cost of building a service and the cost of integrating it into the rest of the system (testing etc). Metrics tell us the magic number sits between five and eight methods per interface with twelve as an upper limit.
As simplicity is number one on our list of non functional requirements I suggest that you make your services stateless, note stateless and state aware are not the same, by stateless I suggest that your services use a per call instantiation pattern unless you have a natural singleton of a really good reason not to.
State is the sworn enemy of scalability, so by remaining per call your system will be able to scale indefinably.
I term these services manager services, as I see them as managing a use case. This technique has saved my bacon in the past as I have had customers that withhold final payment claiming that the system delivered is not what they asked for. If your manger services map one to one to the use cases that they signed off on the process of system validation becomes simple and such customers do not have much of an argument.
Recently I have started using workflow within these manager services to control the flow of logic graphically; I am a firm believer that the development industry is moving towards visual tools for development and future IDE ‘s will not require the developer to write as much code, but rather focus in design more. Workflows come with an overhead as learning this programming model requires a paradigm shift for developers. For simple managers I just code it up the regular way.
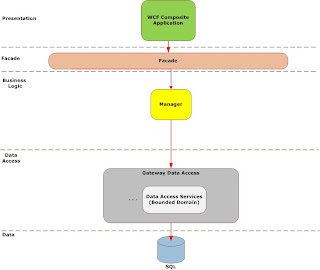
Managers service as the root for transactions I start my transaction scope here for operations that need transactability, operation design is key here, consider splitting interfaces into operations that require transactions and those that do not.
What is cool is that the transaction is cross-process, so you programming model is so much simpler as any enlistable resource you touch is automatically add to the transaction, it even works with message queues. This enables you to program without worrying too much about this sort of thing as you can be sure that a rollback will occur across all the services enlisted if an exception is thrown. You can also consider including the client into your transaction if you have access to their machine and a requirement to do so.
While I am mentioning exceptions, lets discuss this a little, services need to be fault tolerant and bear local responsibility, so that need to handle exceptions graceful, and not burden the client with the details, typically the client can do nothing about exceptions in the service anyway. Writing code to compensate for exceptions is a waste of time; people only cater for the easiest exceptions anyway and conveniently ignore the rest.
There are two types of exceptions you need to know, business exceptions, are the ones you throw to notify users of a violation of business rules, and system exceptions, that the runtime throws, I say catch all system exceptions at the service boundary and log them off to a logging service thus shielding the client from the internal details of the service, throw all business exceptions as FaultException and send back to the user as they can actually do something about it.
Security has not been mentioned at this point, manager service cannot the burdened with the security requirements of any one application as you would typically like to reuse them in multiple applications, but security is more than just authorization and authentication, things like non-repudiation, confidentiality and integrity also play a part. I typically delegate authorization and authentication to an application specific façade layer and handle the rest at the manger service.
By using X509 certificates I can ensure that every packet sent is encrypted and signed to prevent tapering. I can also ensure total end to end security unlike HTTPS. Security is the most intensive thing you can apply to your services, but in my opinion it is non-negotiable and should be by design and not an afterthought. Larger more dispersed and heterogeneous system will require a security token service (STS) look at things like Zermatt to assist you in building these.
In closing we have aligned to tall the things we know make good services in a productive and achievable way, while delegating the heavy lifting to the framework and significantly reducing the amount of plumbing our developers need to write.
Decentralization: Use fully decentralized techniques to remove scaling bottlenecks and single points of failure.
Asynchrony: The system makes progress under all circumstances.
Autonomy: The system is designed such that individual components can make decisions based on local information.
Local responsibility: Each individual component is responsible for achieving its consistency; this is never the burden of its peers.
Controlled concurrency: Operations are designed such that no or limited concurrency control is required.
Failure tolerant: The system considers the failure of components to be a normal mode of operation, and continues operation with no or minimal interruption.
Controlled parallelism: Abstractions used in the system are of such granularity that parallelism can be used to improve performance and robustness of recovery or the introduction of new nodes.
Decompose into small well-understood building blocks: Do not try to provide a single service that does everything for everyone, but instead build small components that can be used as building blocks for other services.
Simplicity: The system should be made as simple as possible (but no simpler).
Just a note at this stage, this type of architecture is for enterprise type systems, these are systems deployed within a organization that run the critical business process, things like data integrity and security are vital. There are many other styles of architecture and we can go into others in future posts. I have a strong bias towards WCF as I believe it to be the most productive framework for building this type of architecture.
I recommend a closed architecture, where objects are allowed to call other objects only in their own tier or in the tier immediately under them. This encapsulates changes and eases the task of long-term maintenance.
At the service boundary services need to support business capabilities, they should have an interface that can be thought of what a business does, and an interface that can the thought of how the business currently does that process. Key here is to keep the what, and the how decoupled from each other.
Decoupling is the cornerstone of modern development, look at the modern patterns that we as an industry subscribe to, notice something? They all hold as a central tenant this notion of decoupling, the removing direct dependency on concrete objects and the enabler of this, dependency injection.
Interfaces allow us to achieve the separation between what and how, so we should take things that are good and try using them elsewhere. Don’t get me wrong, coupling is not all bad we need to be coupled to thing in order for our application to be useful, the decision of choosing what to be coupled to becomes critical.
I have observed that as soon as IT assets and components map well to the real world things work well and systems become really useful. I mentioned earlier that the top level services should map to business capabilities, what are these?
A business capability is a particular ability or capacity that a business may possess or exchange to achieve a specific purpose or outcome. A capability describes what the business does (outcomes and service levels) that create value for customers; for example, pay employee or ship product. A business capability abstracts and encapsulates the people, process/procedures, technology, and information into the essential building blocks needed to facilitate performance improvement and redesign analysis.
So to achieve stable, useful boundary services i.e. the ones exposed to the business people, we need to align them with business capabilities, one technique of achieving this is capability mapping and when applied correctly leads to process driven services.
One of our top non functional is maintainability as the amount of time a system spends in development pales in comparison to the amount of time it will spend in maintenance. With that in mind, the granularity and size of our services should be thought about. Services with hundreds of methods will be un-maintainable while services with one method will be useless; the trick is to find the area of minimum cost between the cost of building a service and the cost of integrating it into the rest of the system (testing etc). Metrics tell us the magic number sits between five and eight methods per interface with twelve as an upper limit.
As simplicity is number one on our list of non functional requirements I suggest that you make your services stateless, note stateless and state aware are not the same, by stateless I suggest that your services use a per call instantiation pattern unless you have a natural singleton of a really good reason not to.
State is the sworn enemy of scalability, so by remaining per call your system will be able to scale indefinably.
I term these services manager services, as I see them as managing a use case. This technique has saved my bacon in the past as I have had customers that withhold final payment claiming that the system delivered is not what they asked for. If your manger services map one to one to the use cases that they signed off on the process of system validation becomes simple and such customers do not have much of an argument.
Recently I have started using workflow within these manager services to control the flow of logic graphically; I am a firm believer that the development industry is moving towards visual tools for development and future IDE ‘s will not require the developer to write as much code, but rather focus in design more. Workflows come with an overhead as learning this programming model requires a paradigm shift for developers. For simple managers I just code it up the regular way.

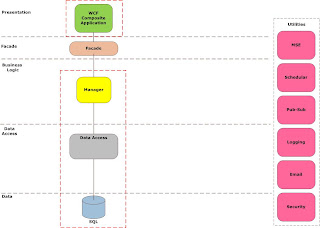
Managers service as the root for transactions I start my transaction scope here for operations that need transactability, operation design is key here, consider splitting interfaces into operations that require transactions and those that do not.
What is cool is that the transaction is cross-process, so you programming model is so much simpler as any enlistable resource you touch is automatically add to the transaction, it even works with message queues. This enables you to program without worrying too much about this sort of thing as you can be sure that a rollback will occur across all the services enlisted if an exception is thrown. You can also consider including the client into your transaction if you have access to their machine and a requirement to do so.
While I am mentioning exceptions, lets discuss this a little, services need to be fault tolerant and bear local responsibility, so that need to handle exceptions graceful, and not burden the client with the details, typically the client can do nothing about exceptions in the service anyway. Writing code to compensate for exceptions is a waste of time; people only cater for the easiest exceptions anyway and conveniently ignore the rest.
There are two types of exceptions you need to know, business exceptions, are the ones you throw to notify users of a violation of business rules, and system exceptions, that the runtime throws, I say catch all system exceptions at the service boundary and log them off to a logging service thus shielding the client from the internal details of the service, throw all business exceptions as FaultException
Security has not been mentioned at this point, manager service cannot the burdened with the security requirements of any one application as you would typically like to reuse them in multiple applications, but security is more than just authorization and authentication, things like non-repudiation, confidentiality and integrity also play a part. I typically delegate authorization and authentication to an application specific façade layer and handle the rest at the manger service.
By using X509 certificates I can ensure that every packet sent is encrypted and signed to prevent tapering. I can also ensure total end to end security unlike HTTPS. Security is the most intensive thing you can apply to your services, but in my opinion it is non-negotiable and should be by design and not an afterthought. Larger more dispersed and heterogeneous system will require a security token service (STS) look at things like Zermatt to assist you in building these.
In closing we have aligned to tall the things we know make good services in a productive and achievable way, while delegating the heavy lifting to the framework and significantly reducing the amount of plumbing our developers need to write.
Friday, October 10, 2008
Formulating an enterprise architecture - Part 1
Tackling the task of formulating architecture for the construction of an enterprise scale system is a daunting one, the architect needs to draw upon multi disciplinary skills, one need to understand the technical details of the selection of technologies available to you, the options in process for constructing solutions as architectures do not all fit well into every process, and experience has taught the when process and architecture are aligned good things happen.
The following post is part one of a series that will present my current thinking around the process of formulating such an architecture. I must confess that most of the ideas are not my own, but I have drawn on the experience and teaching of some of the world best architects to guide me in this. You will find ideas from Juval Lowy, Roger Sessions, Eric Evans, Michele Leroux Bustamante and Bill Poole.
This first post attempts to present an overview, following posts will drill down into the component pieces and flesh out the detail.
Application architecture results from the balancing of functional and the non-functional requirements applicable to the system. Non-functional requirements (restrictions and constraints) serve the purpose of limiting the number of potential solutions that will satisfy a set of functional requirements. Functional requirements are the behaviour that the owner of the system would like to emerge from the development process. All architectures exhibit emergent behaviour. If the emergent behaviours are not specified / managed in the form of non-functional requirements, the developers will choose them on behalf of business, leading to misalignment.
Any new architecture can only result from the balancing of functional and non functional requirements with the forces of time, effort and cost. Every feature, requirement and every non functional requirement carries an associated cost in one of the forces mentioned above.
Architecture is applied at two levels:
·The application architecture addresses the software components of the actual application.
·The systems architecture addresses the physical (hardware) and logical distribution of components across the network environment.
Before any architecture can be formulated the following need to be considered:
Non Functional Requirements
• Simplicity
• Maintainability
• Data Integrity
• Security
• Reporting
• Extensibility
• Scalability
• Deployment
Complexity
The most common aspect shared by all failed systems is the failure to manage complexity. [Sessions] An architecture that fails to mange this aspect is also doomed to fail.
In order to manage complexity we must first understand it, the complexity of a system is a function of the number of states in which a system can find it’s self.
An example is a system (A) that has 3 dice, so the number of potential states is 63 or 216 potential states. Another system (B) with one dice has 61 or 6 potential states, if you where to make repeated guesses for both systems, you would be right, on average 36 times more often with B than you would be with system A. Because system B is less complex and easier to predict
Partitioning
With this basic model of complexity, we can gain some insight into how complexity can be better organised.
Consider another two systems (C) and (D) both have three six sided dice, but in C all the dice are together as before, but in D the dice are divided into three partitions. Let’s assume we can deal with the three partitions independently, in effect, three subsystems each like B. We know that the complexity of C is 216.
The overall complexity of system D is the sum of the complexity of each partition (61 + 61 + 61) or 18. If you are not convinced of this imagine inspecting C and D for correctness in C you would need to examine 216 different states, checking each for correctness. In system D you would need to examine only 6 states in each partition.
The results on how much more complex a non-partitioned system of 9 dice is compared to a partitioned system containing the same number of dice is startling. Ratio of 10,077,696 to 54, a lot!
Process
Just as any architecture will not work with any process, any process will not work with any architecture. Process and architecture are really different manifestations of the same thing.[Lowy]
When formulating any architecture the following graph always remains true.

Process suggested for this development is one of staged delivery as defined in the diagram below.

The axiom is that at any moment in time we have a releasable system; releases may internal type releases or as time progresses and features become apparent, they will be releases to customer. This approach reduces risk as if at the point of release for whatever reason the project is out of time, money etc, what you have may be good enough.
It also facilitates a clear display of progress throughout the development process and builds confidence between development team and customer. Process advocates constant integration with daily builds and tests (smoke tests).
Each component of the system follows a life cycle in order to ensure quality at a service/component level. This is followed by the developer of the component/service.
It would be unprofessional to deploy a distributed system with no means of managing the operational assets deployed. To this end we propose to use service virtualisation to facilitate this process.
 In the next post i will dive deeper into concepts that relate to the service layers and the concept of fortresses.
In the next post i will dive deeper into concepts that relate to the service layers and the concept of fortresses.
The following post is part one of a series that will present my current thinking around the process of formulating such an architecture. I must confess that most of the ideas are not my own, but I have drawn on the experience and teaching of some of the world best architects to guide me in this. You will find ideas from Juval Lowy, Roger Sessions, Eric Evans, Michele Leroux Bustamante and Bill Poole.
This first post attempts to present an overview, following posts will drill down into the component pieces and flesh out the detail.
Application architecture results from the balancing of functional and the non-functional requirements applicable to the system. Non-functional requirements (restrictions and constraints) serve the purpose of limiting the number of potential solutions that will satisfy a set of functional requirements. Functional requirements are the behaviour that the owner of the system would like to emerge from the development process. All architectures exhibit emergent behaviour. If the emergent behaviours are not specified / managed in the form of non-functional requirements, the developers will choose them on behalf of business, leading to misalignment.
Any new architecture can only result from the balancing of functional and non functional requirements with the forces of time, effort and cost. Every feature, requirement and every non functional requirement carries an associated cost in one of the forces mentioned above.
Architecture is applied at two levels:
·The application architecture addresses the software components of the actual application.
·The systems architecture addresses the physical (hardware) and logical distribution of components across the network environment.
Before any architecture can be formulated the following need to be considered:
Non Functional Requirements
• Simplicity
• Maintainability
• Data Integrity
• Security
• Reporting
• Extensibility
• Scalability
• Deployment
Complexity
The most common aspect shared by all failed systems is the failure to manage complexity. [Sessions] An architecture that fails to mange this aspect is also doomed to fail.
In order to manage complexity we must first understand it, the complexity of a system is a function of the number of states in which a system can find it’s self.
An example is a system (A) that has 3 dice, so the number of potential states is 63 or 216 potential states. Another system (B) with one dice has 61 or 6 potential states, if you where to make repeated guesses for both systems, you would be right, on average 36 times more often with B than you would be with system A. Because system B is less complex and easier to predict
Partitioning
With this basic model of complexity, we can gain some insight into how complexity can be better organised.
Consider another two systems (C) and (D) both have three six sided dice, but in C all the dice are together as before, but in D the dice are divided into three partitions. Let’s assume we can deal with the three partitions independently, in effect, three subsystems each like B. We know that the complexity of C is 216.
The overall complexity of system D is the sum of the complexity of each partition (61 + 61 + 61) or 18. If you are not convinced of this imagine inspecting C and D for correctness in C you would need to examine 216 different states, checking each for correctness. In system D you would need to examine only 6 states in each partition.
The results on how much more complex a non-partitioned system of 9 dice is compared to a partitioned system containing the same number of dice is startling. Ratio of 10,077,696 to 54, a lot!
Process
Just as any architecture will not work with any process, any process will not work with any architecture. Process and architecture are really different manifestations of the same thing.[Lowy]
When formulating any architecture the following graph always remains true.

The goal of any architecture is to find that area of minimum cost, the interaction of team members is isomorphic to the interaction between components. A good design (loose coupling, minimised interactions, and encapsulation) minimises the communication overhead both within the team and the system and any process adopted needs to support this.
Best Practice Design Principles
Decentralization: Use fully decentralized techniques to remove scaling bottlenecks and single points of failure.
Asynchrony: The system makes progress under all circumstances.
Autonomy: The system is designed such that individual components can make decisions based on local information.
Local responsibility: Each individual component is responsible for achieving its consistency; this is never the burden of its peers.
Controlled concurrency: Operations are designed such that no or limited concurrency control is required.
Failure tolerant: The system considers the failure of components to be a normal mode of operation, and continues operation with no or minimal interruption.
Controlled parallelism: Abstractions used in the system are of such granularity that parallelism can be used to improve performance and robustness of recovery or the introduction of new nodes.
Decompose into small well-understood building blocks: Do not try to provide a single service that does everything for everyone, but instead build small components that can be used as building blocks for other services.
Simplicity: The system should be made as simple as possible (but no simpler).
Best Practice Design Principles
Decentralization: Use fully decentralized techniques to remove scaling bottlenecks and single points of failure.
Asynchrony: The system makes progress under all circumstances.
Autonomy: The system is designed such that individual components can make decisions based on local information.
Local responsibility: Each individual component is responsible for achieving its consistency; this is never the burden of its peers.
Controlled concurrency: Operations are designed such that no or limited concurrency control is required.
Failure tolerant: The system considers the failure of components to be a normal mode of operation, and continues operation with no or minimal interruption.
Controlled parallelism: Abstractions used in the system are of such granularity that parallelism can be used to improve performance and robustness of recovery or the introduction of new nodes.
Decompose into small well-understood building blocks: Do not try to provide a single service that does everything for everyone, but instead build small components that can be used as building blocks for other services.
Simplicity: The system should be made as simple as possible (but no simpler).
Process - Staged Delivery
Process suggested for this development is one of staged delivery as defined in the diagram below.

This is a very defensive approach as you are able to exit the process at anytime and release what you have or move onto the next stage. We are not going to try to deliver all the requirements at day one as requirements will change during the course of the project.
The axiom is that at any moment in time we have a releasable system; releases may internal type releases or as time progresses and features become apparent, they will be releases to customer. This approach reduces risk as if at the point of release for whatever reason the project is out of time, money etc, what you have may be good enough.
It also facilitates a clear display of progress throughout the development process and builds confidence between development team and customer. Process advocates constant integration with daily builds and tests (smoke tests).
Each component of the system follows a life cycle in order to ensure quality at a service/component level. This is followed by the developer of the component/service.

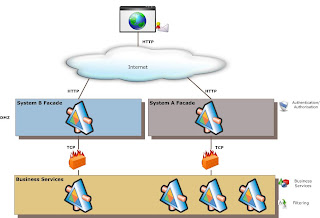
Service Governance
The Managed Services Engine (MSE) is one approach to facilitating Enterprise SOA through service virtualization. Built upon the Windows Communication Foundation (WCF) and the Microsoft Server Platform, the MSE was developed by Microsoft Services as we helped customers address the challenges of SOA in the enterprise.
The MSE fully enables service virtualization through a Service Repository, which helps organizations deploy services faster, coordinate change management, and maximize the reuse of various service elements. In doing so, the MSE provides the ability to support versioning, abstraction, management, routing, and runtime policy enforcement for Services
Proposed Architecture
In the next post i will dive deeper into concepts that relate to the service layers and the concept of fortresses.Thursday, September 11, 2008
Design Principles
I am currently involved in the design phase of a project for a client, and have been thinking a lot about design principles, the sort of things that apply to all technologies and projects equally.
Readers of the blog will know that I have strong ideas on design and architectural form, but I felt a sense of validation when I came across a set of design principles that Amazon uses in the formulation of their elastic cloud technology stack.
The principles here map almost one to one to those which I hold and apply daily to my projects and architectures, these include:
Symmetry I perhaps use a bit differently, I apply it to the design of components, where by one component although different in function follows the same structure and layout of the others, so every bit of the system is symmetric to the others with regards to standards and layout.
Follow these, and good things will follow I promise!
I believe that process and architecture are different aspects of the same thing, so by aligning these principles with an architecture and process that support them you are putting blocks into place that will lead to success.
Readers of the blog will know that I have strong ideas on design and architectural form, but I felt a sense of validation when I came across a set of design principles that Amazon uses in the formulation of their elastic cloud technology stack.
The principles here map almost one to one to those which I hold and apply daily to my projects and architectures, these include:
- Decentralization: Use fully decentralized techniques to remove scaling bottlenecks and single points of failure.
- Asynchrony: The system makes progress under all circumstances.
- Autonomy: The system is designed such that individual components can make decisions based on local information.
- Local responsibility: Each individual component is responsible for achieving its consistency; this is never the burden of its peers.
- Controlled concurrency: Operations are designed such that no or limited concurrency control is required.
- Failure tolerant: The system considers the failure of components to be a normal mode of operation, and continues operation with no or minimal interruption.
- Controlled parallelism: Abstractions used in the system are of such granularity that parallelism can be used to improve performance and robustness of recovery or the introduction of new nodes.
Decompose into small well-understood building blocks: Do not try to provide a single service that does everything for everyone, but instead build small components that can be used as building blocks for other services. - Symmetry: Nodes in the system are identical in terms of functionality, and require no or minimal node-specific configuration to function.
- Simplicity: The system should be made as simple as possible (but no simpler).
Symmetry I perhaps use a bit differently, I apply it to the design of components, where by one component although different in function follows the same structure and layout of the others, so every bit of the system is symmetric to the others with regards to standards and layout.
Follow these, and good things will follow I promise!
I believe that process and architecture are different aspects of the same thing, so by aligning these principles with an architecture and process that support them you are putting blocks into place that will lead to success.
Monday, August 25, 2008
Elastic cloud, S+S, how can I take advantage?
Admittedly I was also a bit confused when I first heard the term Software + Services (S+S); I just presumed that it was a mispronunciation of Software as a Service.
Let me sum up my understanding of this term and what it means to architects, IT managers and developers:
S+S is an architectural style that seeks to move IT services and infrastructure out of the enterprise and into the cloud.
We all know that services are a good thing, and if designed correctly i.e. process centric based on autonomous business capabilities with a decentralized data model, they can be a tremendous asset to an organization.
Which is great if you have servers, networks, VPN, etc, but what if you have a really good idea, but what to keep costs down, or if you are a CIO looking to reduce costs?
Enter S+S and the concept of federation, the idea io this is closely tied up with the trend we are seeing in businesses pushed by globalization and competitive forces, the classic, linear supply chain has evolved into a complex value network of partners participating in a common business.
Federation aligns nicely with this trend and clever businesses will be looking at outsourcing their non-core business capabilities. What are these? Think of things like database management, identity management, hosting of their internal and client facing applications, SMS and cellular communication applications, this is endless and growing as more service providers add more services to the domain.
And for many businesses this really makes sense, rather than a large capital expenditure on hardware, and maintaining a staff of potential substandard and expensive IT resources, you move your expenditure to an operational one and get the support of some of the best professionals in the world as well as access to some of the most advanced data centers currently in existence.
The ability to only pay for what you use is a great opportunity for business to become more innovative as the cost of failure is much less. It also lowers the entry criteria for small business as they can offer enterprise like applications and infrastructure at fractions of the normal cost.
Leaders in the S+S space are Google and Amazon, Amazon Web Services offering file storage, database, connectivity and an application hosting engine see http://www.amazon.com/AWS-home-page-Money/b?ie=UTF8&node=3435361 and Google with application hosting see http://code.google.com/appengine/
As part of their future strategy Microsoft have committed to getting into this space in a big way, projects Red-dog and Zurich promise to bring Microsoft server platform into the cloud, and combined with the current and future offerings of the Live platform will provide some phenomenal opportunities to business in the near future.
You can go have an early look at SQL Server Data Services which are in a preliminary release format at http://msdn.microsoft.com/en-us/library/cc512402.aspx.
BizTalk connectivity services currently allows disparate networks to communicate without any additional hardware, Live Id offers to remove security woes and the grand plan of Project Oslo seeks to deliver it all up as a cohesive development and administration platform.
British Telecom has a fantastic S+S API out in the form of the WEB21C SDK which integrates SMS, cellular and telephony into applications easily, see http://web21c.bt.com/services
These are exiting times and I intend to embrace the Zeitgeist, I believe that S+S represents the way forward for small to medium enterprises, as well as a great vehicle for IT entrepreneurs.
Let me sum up my understanding of this term and what it means to architects, IT managers and developers:
S+S is an architectural style that seeks to move IT services and infrastructure out of the enterprise and into the cloud.
We all know that services are a good thing, and if designed correctly i.e. process centric based on autonomous business capabilities with a decentralized data model, they can be a tremendous asset to an organization.
Which is great if you have servers, networks, VPN, etc, but what if you have a really good idea, but what to keep costs down, or if you are a CIO looking to reduce costs?
Enter S+S and the concept of federation, the idea io this is closely tied up with the trend we are seeing in businesses pushed by globalization and competitive forces, the classic, linear supply chain has evolved into a complex value network of partners participating in a common business.
Federation aligns nicely with this trend and clever businesses will be looking at outsourcing their non-core business capabilities. What are these? Think of things like database management, identity management, hosting of their internal and client facing applications, SMS and cellular communication applications, this is endless and growing as more service providers add more services to the domain.
And for many businesses this really makes sense, rather than a large capital expenditure on hardware, and maintaining a staff of potential substandard and expensive IT resources, you move your expenditure to an operational one and get the support of some of the best professionals in the world as well as access to some of the most advanced data centers currently in existence.
The ability to only pay for what you use is a great opportunity for business to become more innovative as the cost of failure is much less. It also lowers the entry criteria for small business as they can offer enterprise like applications and infrastructure at fractions of the normal cost.
Leaders in the S+S space are Google and Amazon, Amazon Web Services offering file storage, database, connectivity and an application hosting engine see http://www.amazon.com/AWS-home-page-Money/b?ie=UTF8&node=3435361 and Google with application hosting see http://code.google.com/appengine/
As part of their future strategy Microsoft have committed to getting into this space in a big way, projects Red-dog and Zurich promise to bring Microsoft server platform into the cloud, and combined with the current and future offerings of the Live platform will provide some phenomenal opportunities to business in the near future.
You can go have an early look at SQL Server Data Services which are in a preliminary release format at http://msdn.microsoft.com/en-us/library/cc512402.aspx.
BizTalk connectivity services currently allows disparate networks to communicate without any additional hardware, Live Id offers to remove security woes and the grand plan of Project Oslo seeks to deliver it all up as a cohesive development and administration platform.
British Telecom has a fantastic S+S API out in the form of the WEB21C SDK which integrates SMS, cellular and telephony into applications easily, see http://web21c.bt.com/services
These are exiting times and I intend to embrace the Zeitgeist, I believe that S+S represents the way forward for small to medium enterprises, as well as a great vehicle for IT entrepreneurs.
Friday, August 1, 2008
Tech-Ed Durban 2008
I am off to Tech-Ed on Sunday, and this year I am following a mainly SOA track with a bit of dev thrown in.
Ron Jacobs’s sessions on WCF and WWF promise to be great, I have seen his sessions from Barcelona, and have been an avid Arcast.TV watcher/listener for years, so it will be great to see the man in person.
Speakers like Steve Riley and Shy Cohen also have some great sessions that I will not be missing.
It will also be interesting to see how the speakers handle questions around the Entity Framework and LINQ to SQL, as there will be some of South Africa’s largest Development shops present and many of the guys there have been using these products in the wild and will have a ton of questions.
Good to see some top South African speakers like Hilton Giesenow and Ayal Rosenberg I always enjoy their sessions.
Please feel free to look me up at the conference and have a chat, looking forward to seeing you all there.
Ron Jacobs’s sessions on WCF and WWF promise to be great, I have seen his sessions from Barcelona, and have been an avid Arcast.TV watcher/listener for years, so it will be great to see the man in person.
Speakers like Steve Riley and Shy Cohen also have some great sessions that I will not be missing.
It will also be interesting to see how the speakers handle questions around the Entity Framework and LINQ to SQL, as there will be some of South Africa’s largest Development shops present and many of the guys there have been using these products in the wild and will have a ton of questions.
Good to see some top South African speakers like Hilton Giesenow and Ayal Rosenberg I always enjoy their sessions.
Please feel free to look me up at the conference and have a chat, looking forward to seeing you all there.
Monday, July 28, 2008
SOA and Anemic Domains
After a conversation with a work college of mine I was amazed to find that many people have not made the mind shift into a SOA way of thinking.
Most are in the 80’s with a pure OO paradigm; it’s a brave new world people, OO and its promise of reuse failed, no one ever reused pure business objects as is, ever.
The unit of reuse has moved from sharing code to delegation of functionality, the artifact of reuse has shifted from the object to the service. Don’t talk about sending objects around, rather keep the objects where they belong and send messages asking a service to perform actions on them.
They shout out, “but you have an Anemic Domain, it’s an anti pattern so you must be wrong”.
Are they suggesting distributed systems that pass around "real" objects, behaviour and all? You should cry out in terror at the thought of using such a system in production.
For an OO purist the domain model is the most important part, but for the enterprise the database is far more important, seen by the fact that many databases far outlive the applications built to access them.
In SOA land your OO business logic is not the only business logic involved here, your services are part of a large interacting web of autonomous services, some wrapping legacy systems, is their business logic any less important.
I say design your services right, services that are self contained, process/capability driven, have de-centralised data and which communicate via well defined messages will lead to deliverable architectures, nobody will care how elegant your business layer is if you never get it done on time.
Most are in the 80’s with a pure OO paradigm; it’s a brave new world people, OO and its promise of reuse failed, no one ever reused pure business objects as is, ever.
The unit of reuse has moved from sharing code to delegation of functionality, the artifact of reuse has shifted from the object to the service. Don’t talk about sending objects around, rather keep the objects where they belong and send messages asking a service to perform actions on them.
They shout out, “but you have an Anemic Domain, it’s an anti pattern so you must be wrong”.
Are they suggesting distributed systems that pass around "real" objects, behaviour and all? You should cry out in terror at the thought of using such a system in production.
For an OO purist the domain model is the most important part, but for the enterprise the database is far more important, seen by the fact that many databases far outlive the applications built to access them.
In SOA land your OO business logic is not the only business logic involved here, your services are part of a large interacting web of autonomous services, some wrapping legacy systems, is their business logic any less important.
I say design your services right, services that are self contained, process/capability driven, have de-centralised data and which communicate via well defined messages will lead to deliverable architectures, nobody will care how elegant your business layer is if you never get it done on time.
Friday, July 11, 2008
What is maintenance?
I have been doing some work analysing some legacy systems, some old some brand new, yes it is possible to write a brand new legacy system!
I thought it would be good to define what maintenance is and what can be done to make it a less painful exercise down the road.
After a product has been released, the maintenance phase keeps the software up to date with environment changes and changing user requirements.
The earlier phases should be done correctly so that the product is easily maintainable. The design phase should plan the structure in a way that can be easily altered. Similarly, the implementation phase should create code that can be easily read, understood, and changed.
Maintenance can only happen efficiently if the earlier phases are done properly. There are three major problems that can slow down the maintenance process: unstructured code, maintenance programmers having insufficient knowledge of the system and documentation being absent, out of date, or at best insufficient.
The success of the maintenance phase relies on these problems being fixed earlier in the life cycle.
Maintenance consists of four parts.
Corrective maintenance deals with fixing bugs in the code. Adaptive maintenance deals with adapting the software to new environments. Perfective maintenance deals with updating the software according to changes in user requirements.
Finally, preventive maintenance deals with updating documentation and making the software more maintainable.
All changes to the system can be characterized by these four types of maintenance. Corrective maintenance is ‘traditional maintenance’ while the other types are considered as ‘software evolution.’
As software systems age, it becomes increasingly difficult to keep them ‘up and running’ without maintenance.
There is direct financial cost of not maintaining software systems, and in fact, a substantial proportion of the resources expended within the Information Technology industry go towards the maintenance of software systems.
In order to increase the maintainability of software, we need to know what characteristics of a product affect its maintainability.
There has been a great deal of speculation about what makes a software system more difficult to maintain. There are some program characteristics that are found to affect a product’s maintainability
Factors include system size, system age, number of input/output data items, application type, programming language, and the degree of structure.
Larger systems require more maintenance effort than do smaller systems, because there is a greater learning curve associated with larger systems, and larger systems are more complex in terms of the variety of functions they perform.
Older systems require more maintenance effort than do younger systems, because software systems tend to grow larger with age, become less organized with changes, and become less understandable due to staff turnover.
The factors that decrease maintenance effort can be summarised into the list below:
· Use of structured techniques
· Use of modern software
· Use of automated tools
· Use of data-base techniques
· Good data administration
· Experienced maintainers.
I thought it would be good to define what maintenance is and what can be done to make it a less painful exercise down the road.
After a product has been released, the maintenance phase keeps the software up to date with environment changes and changing user requirements.
The earlier phases should be done correctly so that the product is easily maintainable. The design phase should plan the structure in a way that can be easily altered. Similarly, the implementation phase should create code that can be easily read, understood, and changed.
Maintenance can only happen efficiently if the earlier phases are done properly. There are three major problems that can slow down the maintenance process: unstructured code, maintenance programmers having insufficient knowledge of the system and documentation being absent, out of date, or at best insufficient.
The success of the maintenance phase relies on these problems being fixed earlier in the life cycle.
Maintenance consists of four parts.
Corrective maintenance deals with fixing bugs in the code. Adaptive maintenance deals with adapting the software to new environments. Perfective maintenance deals with updating the software according to changes in user requirements.
Finally, preventive maintenance deals with updating documentation and making the software more maintainable.
All changes to the system can be characterized by these four types of maintenance. Corrective maintenance is ‘traditional maintenance’ while the other types are considered as ‘software evolution.’
As software systems age, it becomes increasingly difficult to keep them ‘up and running’ without maintenance.
There is direct financial cost of not maintaining software systems, and in fact, a substantial proportion of the resources expended within the Information Technology industry go towards the maintenance of software systems.
In order to increase the maintainability of software, we need to know what characteristics of a product affect its maintainability.
There has been a great deal of speculation about what makes a software system more difficult to maintain. There are some program characteristics that are found to affect a product’s maintainability
Factors include system size, system age, number of input/output data items, application type, programming language, and the degree of structure.
Larger systems require more maintenance effort than do smaller systems, because there is a greater learning curve associated with larger systems, and larger systems are more complex in terms of the variety of functions they perform.
Older systems require more maintenance effort than do younger systems, because software systems tend to grow larger with age, become less organized with changes, and become less understandable due to staff turnover.
The factors that decrease maintenance effort can be summarised into the list below:
· Use of structured techniques
· Use of modern software
· Use of automated tools
· Use of data-base techniques
· Good data administration
· Experienced maintainers.
Friday, June 27, 2008
Non Functional requirements driving technology choice
With the slue of new technologies out of Microsoft over the past 2 years,
WCF, WWF, WPF, Silverlight, LINQ, Entity Framework, ADO.NET Data Services, MVC Framework, ASP AJAX etc... It is becoming increasingly confusing for developers to figure out what technologies to use, and how and where to apply them.
The danger facing many new projects is to fall into the trap of using a technology because it is new, rather than a good fit to the requirements of the problem at hand.
I always start with the non functional requirements before making any decision about the implementation technology.
Application architecture results from the balancing of functional and the non-functional requirements applicable to the system. Non-functional requirements (restrictions and constraints) serve the purpose of limiting the number of potential solutions that will satisfy a set of functional requirements.
Functional requirements are the behaviour that the owner of the system would like to emerge from the development process. All architectures exhibit emergent behaviour. If the emergent behaviours are not specified / managed in the form of non-functional requirements, the developers will choose them on behalf of business, leading to misalignment.
Architecture is applied at two levels:
·The application architecture addresses the software components of the actual application.
·The systems architecture addresses the physical (hardware) and logical distribution of components across the network environment.
The non-functional aspects that I usually consider when formulating architecture
Simplicity - number one non functional
Security – this requirement in my opinion is not an option, the five pillars of Authentication, Authorisation, Integrity, Confidentiality, and Non-repudiation need to be catered for in any application you design.
Performance – here I am looking at things like number of online transactions, batch runs and if applicable the throughput from a users perspective. The last one is quite important as to a user of any system with a front end, this is all that matters, this requirement often allows you to factor the system to cater for the different expectations that will be imposed in the system by its users.
Maintainability - The ease with which code can be understood and changed, the aspect of maintainability should be pervasive throughout any architecture you design, any item must be created with the eye towards maintaining it.
Integrity - Ability to detect and manage invalid data coming in to system and the imposition of complete transactions or rollbacks.
Extensibility - Ease with which new features can be added to the code, not the same as maintainability, things like composite applications work really well here.
Flexibility - Ease with which the software can be deployed in different environments.
Scalability - Ability of the system to grow with the organisation without code changes, increase in number of users, increase in number of transactions.
As you would have noticed, many of these requirements are in direct opposition of each other; in conjunction to this there is a price to pay for achieving any of them fully.
As a software architect the responsibility is on you to attempt to balance these conflicting forces and find the best alignment to fit the system specifications.
It is also your task to align technology risks with the appetite for risk of the organisation.
By evaluating the system against these non functional requirements first I find that my options of implementation technology usually get reduced into a manageable set.
WCF, WWF, WPF, Silverlight, LINQ, Entity Framework, ADO.NET Data Services, MVC Framework, ASP AJAX etc... It is becoming increasingly confusing for developers to figure out what technologies to use, and how and where to apply them.
The danger facing many new projects is to fall into the trap of using a technology because it is new, rather than a good fit to the requirements of the problem at hand.
I always start with the non functional requirements before making any decision about the implementation technology.
Application architecture results from the balancing of functional and the non-functional requirements applicable to the system. Non-functional requirements (restrictions and constraints) serve the purpose of limiting the number of potential solutions that will satisfy a set of functional requirements.
Functional requirements are the behaviour that the owner of the system would like to emerge from the development process. All architectures exhibit emergent behaviour. If the emergent behaviours are not specified / managed in the form of non-functional requirements, the developers will choose them on behalf of business, leading to misalignment.
Architecture is applied at two levels:
·The application architecture addresses the software components of the actual application.
·The systems architecture addresses the physical (hardware) and logical distribution of components across the network environment.
The non-functional aspects that I usually consider when formulating architecture
Simplicity - number one non functional
Security – this requirement in my opinion is not an option, the five pillars of Authentication, Authorisation, Integrity, Confidentiality, and Non-repudiation need to be catered for in any application you design.
Performance – here I am looking at things like number of online transactions, batch runs and if applicable the throughput from a users perspective. The last one is quite important as to a user of any system with a front end, this is all that matters, this requirement often allows you to factor the system to cater for the different expectations that will be imposed in the system by its users.
Maintainability - The ease with which code can be understood and changed, the aspect of maintainability should be pervasive throughout any architecture you design, any item must be created with the eye towards maintaining it.
Integrity - Ability to detect and manage invalid data coming in to system and the imposition of complete transactions or rollbacks.
Extensibility - Ease with which new features can be added to the code, not the same as maintainability, things like composite applications work really well here.
Flexibility - Ease with which the software can be deployed in different environments.
Scalability - Ability of the system to grow with the organisation without code changes, increase in number of users, increase in number of transactions.
As you would have noticed, many of these requirements are in direct opposition of each other; in conjunction to this there is a price to pay for achieving any of them fully.
As a software architect the responsibility is on you to attempt to balance these conflicting forces and find the best alignment to fit the system specifications.
It is also your task to align technology risks with the appetite for risk of the organisation.
By evaluating the system against these non functional requirements first I find that my options of implementation technology usually get reduced into a manageable set.
Wednesday, June 25, 2008
Mix Essentials 2008
I attended the Mix Essentials at Monte casino yesterday, a big thanks to the organizers for a great venue and for organizing Brad Abrams.
South African developers have been a bit deprived in getting to meet the legends of the business, I was fortunate to meet Juval Lowe last year at Dariel Solutions WCF Master Class, and with Brad coming out this year things are definitely looking up.
Silverlight was the focus of the event, and it looks great, and it has good tool support in the form of Blend. Would I use it? Maybe, as a developer the touchy feely artistic side of UI development has never really got me excited, but I understand that the UX is all that a user sees and it can make or break any application.
I think the success of this platform will depend on its uptake in the designer community who already has a large investment in Flash. I as a developer will not be moving my web apps to Silverlight soon, but I can see myself incorporating pieces of Silverlight into ASP AJAX sites where a bit of bling is needed.
Good news is that ASP.NET AJAX is here to stay; Silverlight for now is aimed at RIA’s (Rich Internet Applications). The contracts to build such applications usually go to advertising agencies and graphic designers, not hard core development houses.
Dev shops need to know about Silverlight, and its capabilities and can leverage it to add to the UX of their offerings, but I do not see it replacing ASP.NET AJAX for line of business applications just yet.
I followed the developer track, and really nothing earth shattering was on show, Brad demoed ASP AJAX which we have been using for years now, nice that it has been built into VS 2008, but you still need to get the toolkit for all the latest controls.
This is becoming a mature platform, there are lots of great controls, and optimizations available.
MVC framework is a great project to watch in the future I feel that it is still a bit immature as it is today, but it is a great idea. The routing engine is clever and having the ability to use URL mapping rules to handle both incoming and outgoing URL scenarios adds a lot of flexibility to application code.
It means that if we want to later change the URL structure of our application (for example: rename /Products to /Catalog), we could do so by modifying one set of mapping rules at the application level - and not require changing any code within our Controllers or View templates.
Brad hinted that versions of MVC for WPF and Win Forms are in the pipeline. Could he be alluding to the WPF Composite client project, a rebuild of CAB for WPF?
Dynamic Data was on show, this seems like the BLINQ project renamed, it currently only works with LINQ to SQL, but Entity framework will follow soon. It is fully customizable and could be a great time saver in certain projects.
South African developers have been a bit deprived in getting to meet the legends of the business, I was fortunate to meet Juval Lowe last year at Dariel Solutions WCF Master Class, and with Brad coming out this year things are definitely looking up.
Silverlight was the focus of the event, and it looks great, and it has good tool support in the form of Blend. Would I use it? Maybe, as a developer the touchy feely artistic side of UI development has never really got me excited, but I understand that the UX is all that a user sees and it can make or break any application.
I think the success of this platform will depend on its uptake in the designer community who already has a large investment in Flash. I as a developer will not be moving my web apps to Silverlight soon, but I can see myself incorporating pieces of Silverlight into ASP AJAX sites where a bit of bling is needed.
Good news is that ASP.NET AJAX is here to stay; Silverlight for now is aimed at RIA’s (Rich Internet Applications). The contracts to build such applications usually go to advertising agencies and graphic designers, not hard core development houses.
Dev shops need to know about Silverlight, and its capabilities and can leverage it to add to the UX of their offerings, but I do not see it replacing ASP.NET AJAX for line of business applications just yet.
I followed the developer track, and really nothing earth shattering was on show, Brad demoed ASP AJAX which we have been using for years now, nice that it has been built into VS 2008, but you still need to get the toolkit for all the latest controls.
This is becoming a mature platform, there are lots of great controls, and optimizations available.
MVC framework is a great project to watch in the future I feel that it is still a bit immature as it is today, but it is a great idea. The routing engine is clever and having the ability to use URL mapping rules to handle both incoming and outgoing URL scenarios adds a lot of flexibility to application code.
It means that if we want to later change the URL structure of our application (for example: rename /Products to /Catalog), we could do so by modifying one set of mapping rules at the application level - and not require changing any code within our Controllers or View templates.
Brad hinted that versions of MVC for WPF and Win Forms are in the pipeline. Could he be alluding to the WPF Composite client project, a rebuild of CAB for WPF?
Dynamic Data was on show, this seems like the BLINQ project renamed, it currently only works with LINQ to SQL, but Entity framework will follow soon. It is fully customizable and could be a great time saver in certain projects.
Tuesday, June 17, 2008
Why Metal Lemon?
Metal Lemon is a play on the classic saying when life gives you lemons make lemonade, well lemonade is useful, but power is even more useful , a lemon, a nail and a piece of copper can be used to make a battery, if you have enough you have the potential to power anything, so take lifes lemons and turn them into something potentially great.
Subscribe to:
Posts (Atom)

{kind=link}
{kind=link}