Decentralization: Use fully decentralized techniques to remove scaling bottlenecks and single points of failure.
Asynchrony: The system makes progress under all circumstances.
Autonomy: The system is designed such that individual components can make decisions based on local information.
Local responsibility: Each individual component is responsible for achieving its consistency; this is never the burden of its peers.
Controlled concurrency: Operations are designed such that no or limited concurrency control is required.
Failure tolerant: The system considers the failure of components to be a normal mode of operation, and continues operation with no or minimal interruption.
Controlled parallelism: Abstractions used in the system are of such granularity that parallelism can be used to improve performance and robustness of recovery or the introduction of new nodes.
Decompose into small well-understood building blocks: Do not try to provide a single service that does everything for everyone, but instead build small components that can be used as building blocks for other services.
Simplicity: The system should be made as simple as possible (but no simpler).
Just a note at this stage, this type of architecture is for enterprise type systems, these are systems deployed within a organization that run the critical business process, things like data integrity and security are vital. There are many other styles of architecture and we can go into others in future posts. I have a strong bias towards WCF as I believe it to be the most productive framework for building this type of architecture.
I recommend a closed architecture, where objects are allowed to call other objects only in their own tier or in the tier immediately under them. This encapsulates changes and eases the task of long-term maintenance.
At the service boundary services need to support business capabilities, they should have an interface that can be thought of what a business does, and an interface that can the thought of how the business currently does that process. Key here is to keep the what, and the how decoupled from each other.
Decoupling is the cornerstone of modern development, look at the modern patterns that we as an industry subscribe to, notice something? They all hold as a central tenant this notion of decoupling, the removing direct dependency on concrete objects and the enabler of this, dependency injection.
Interfaces allow us to achieve the separation between what and how, so we should take things that are good and try using them elsewhere. Don’t get me wrong, coupling is not all bad we need to be coupled to thing in order for our application to be useful, the decision of choosing what to be coupled to becomes critical.
I have observed that as soon as IT assets and components map well to the real world things work well and systems become really useful. I mentioned earlier that the top level services should map to business capabilities, what are these?
A business capability is a particular ability or capacity that a business may possess or exchange to achieve a specific purpose or outcome. A capability describes what the business does (outcomes and service levels) that create value for customers; for example, pay employee or ship product. A business capability abstracts and encapsulates the people, process/procedures, technology, and information into the essential building blocks needed to facilitate performance improvement and redesign analysis.
So to achieve stable, useful boundary services i.e. the ones exposed to the business people, we need to align them with business capabilities, one technique of achieving this is capability mapping and when applied correctly leads to process driven services.
One of our top non functional is maintainability as the amount of time a system spends in development pales in comparison to the amount of time it will spend in maintenance. With that in mind, the granularity and size of our services should be thought about. Services with hundreds of methods will be un-maintainable while services with one method will be useless; the trick is to find the area of minimum cost between the cost of building a service and the cost of integrating it into the rest of the system (testing etc). Metrics tell us the magic number sits between five and eight methods per interface with twelve as an upper limit.
As simplicity is number one on our list of non functional requirements I suggest that you make your services stateless, note stateless and state aware are not the same, by stateless I suggest that your services use a per call instantiation pattern unless you have a natural singleton of a really good reason not to.
State is the sworn enemy of scalability, so by remaining per call your system will be able to scale indefinably.
I term these services manager services, as I see them as managing a use case. This technique has saved my bacon in the past as I have had customers that withhold final payment claiming that the system delivered is not what they asked for. If your manger services map one to one to the use cases that they signed off on the process of system validation becomes simple and such customers do not have much of an argument.
Recently I have started using workflow within these manager services to control the flow of logic graphically; I am a firm believer that the development industry is moving towards visual tools for development and future IDE ‘s will not require the developer to write as much code, but rather focus in design more. Workflows come with an overhead as learning this programming model requires a paradigm shift for developers. For simple managers I just code it up the regular way.

Managers service as the root for transactions I start my transaction scope here for operations that need transactability, operation design is key here, consider splitting interfaces into operations that require transactions and those that do not.
What is cool is that the transaction is cross-process, so you programming model is so much simpler as any enlistable resource you touch is automatically add to the transaction, it even works with message queues. This enables you to program without worrying too much about this sort of thing as you can be sure that a rollback will occur across all the services enlisted if an exception is thrown. You can also consider including the client into your transaction if you have access to their machine and a requirement to do so.
While I am mentioning exceptions, lets discuss this a little, services need to be fault tolerant and bear local responsibility, so that need to handle exceptions graceful, and not burden the client with the details, typically the client can do nothing about exceptions in the service anyway. Writing code to compensate for exceptions is a waste of time; people only cater for the easiest exceptions anyway and conveniently ignore the rest.
There are two types of exceptions you need to know, business exceptions, are the ones you throw to notify users of a violation of business rules, and system exceptions, that the runtime throws, I say catch all system exceptions at the service boundary and log them off to a logging service thus shielding the client from the internal details of the service, throw all business exceptions as FaultException
Security has not been mentioned at this point, manager service cannot the burdened with the security requirements of any one application as you would typically like to reuse them in multiple applications, but security is more than just authorization and authentication, things like non-repudiation, confidentiality and integrity also play a part. I typically delegate authorization and authentication to an application specific façade layer and handle the rest at the manger service.
By using X509 certificates I can ensure that every packet sent is encrypted and signed to prevent tapering. I can also ensure total end to end security unlike HTTPS. Security is the most intensive thing you can apply to your services, but in my opinion it is non-negotiable and should be by design and not an afterthought. Larger more dispersed and heterogeneous system will require a security token service (STS) look at things like Zermatt to assist you in building these.
In closing we have aligned to tall the things we know make good services in a productive and achievable way, while delegating the heavy lifting to the framework and significantly reducing the amount of plumbing our developers need to write.



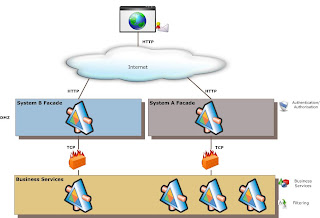 In the next post i will dive deeper into concepts that relate to the service layers and the concept of fortresses.
In the next post i will dive deeper into concepts that relate to the service layers and the concept of fortresses.
{kind=link}
{kind=link}